问题调试¶
主要作者
本文已完成,等待校对
本部分介绍调试问题时的一般思路和方法。 请注意本部分无法面面俱到,因此只能够提供一些在运维上常用的方法,具体问题需要具体分析。
快速检查单¶
以下提供在系统遇到异常情况时,可以快速检查的一些项目:
- 系统负载
uptime可以查看系统在过去 1 分钟、5 分钟、15 分钟的平均负载——这里的「负载」指的是正在等待 CPU 的进程数量(包括陷入不可中断睡眠的进程,大多数情况下处于这种状态的进程都在等待磁盘 I/O)。- PSI(Pressure Stall Information)信息可以确认系统的具体的压力情况。在
/proc/pressure目录下可以看到 CPU、I/O、IRQ 以及内存的压力情况。在每个文件中,some代表至少一些进程需要等待对应资源的时间比例(0 到 100),full代表所有进程需要等待对应资源的时间比例。- PSI 可以精确到 cgroup——每个 cgroup 下的
*.pressure就是对应的压力信息。
- PSI 可以精确到 cgroup——每个 cgroup 下的
htop可以快速查看系统的 CPU、内存(包括 swap)以及进程情况。在进程数量很多的时候,top的性能会更好一些(虽然易用性不如htop)。iostat 1可以每隔 1 秒输出一次磁盘 I/O 情况。
- 系统日志
journalctl -fdmesg -w
- 资源使用情况
df -h可以查看磁盘空间使用情况。iotop可以按进程查看磁盘 I/O 情况。- iotop 有两个不同的版本,在各个发行版中一般分为
iotop和iotop-c。前者已经停止维护,因此推荐安装iotop-c。
- iotop 有两个不同的版本,在各个发行版中一般分为
iftop可以查看对应接口的网络流量情况。- 如果需要按进程查看网络流量情况,可以使用
nethogs。
- 如果需要按进程查看网络流量情况,可以使用
系统几乎/完全无法操作
不幸的是,有些时候出现问题的系统会卡在那里,无法操作,这可能是因为内存几乎已满,出现了大量 I/O 操作,也有可能是内核崩溃或是硬件问题。如果内核仍然在运行,可以尝试使用 SysRq 快捷键做一些操作。如果机器没有 SysRq 按键(例如笔记本电脑),可以使用 PrintScreen 键代替。
根据发行版配置的不同,默认情况下仅允许有限的 SysRq 操作,可以向 /proc/sys/kernel/sysrq 写入 1 来运行全部操作,或者自行计算允许的操作,详情见 Linux 内核文档的 "Linux Magic System Request Key Hacks" 部分。需要在 sysctl 配置中设置 kernel.sysrq=1 以持久化相应设置。
最常见的 SysRq 系列指令为 REISUB(即 busy 的比较级 busier 反过来),即按顺序按下 Alt+SysRq+R、E、I、S、U、B,分别对应的操作为:
- (un)R(aw):修改键盘模式到 ASCII(XLATE),一般用于从 X 桌面环境夺取键盘控制。
- t(E)rm:发送 SIGTERM 信号给所有进程。
- k(I)ll:发送 SIGKILL 信号给所有进程。
- (S)ync:将所有已挂载文件系统的缓冲区数据写入磁盘。
- (U)nmount:重新挂载所有文件系统为只读模式。
- re(B)oot:重启系统。
如果确信问题是由于某些进程占用大量内存导致的,可以使用 Alt+SysRq+F 来触发内核的 OOM Killer。其他的操作可以参考以上内核文档链接。
服务状态与日志¶
当出现异常,登录系统后,第一件事情可能是检查当前系统的服务状态。
systemctl --failed 可以列出当前失败的服务。
如果显示大量服务失败,那么说明可能遇到了比较严重的问题,例如磁盘已满等。
可以先尝试将失败的服务恢复。systemctl status 可以列出当前系统中的 cgroup 情况(约等于所有正在运行的服务以及进程的树)。
检查日志内容也是检查、排除问题的重要步骤。 现代基于 systemd 的 Linux 系统的日志通常由 systemd-journald 负责管理。 以下是常用的命令:
journalctl -b: 查看本次开机的日志。在-b后加上-1/-2等可以查看上次/上上次等的开机日志。journalctl --since "1 hour ago": 查看最近一小时的日志。journalctl -u xxx.service: 查看某个服务的日志。journalctl -f: 实时查看日志。journalctl -b -k: 查看本次启动的内核态日志。dmesg的命令虽然也可以查看,但是因为内核内存有限,所以可能看不到较早的内核态日志信息。 journald 会帮我们持久化内核态日志信息。
journalctl 默认会使用 pager(换句话说,less)显示日志,当然也可以后面接个 | grep ... 来过滤日志。
此外,如果使用了用户服务(user service),那么检查用户服务的状态或者日志时,需要加上 --user 参数。
大部分的 Debian 系统会预装 rsyslog,它会将 journald 的日志转发到 /var/log/syslog,可以直接使用常规的命令行文本处理工具分析。
其他一些软件可能也不会使用 journald,而是直接将日志写入到 /var/log/ 目录下的文件中,例如 nginx。
logrotate 会定期(一般是每天,或者文件足够大的时候,请参考 /etc/logrotate* 对应的配置)「轮转」(rotate)日志文件:
这是一个将旧日志压缩,更旧的日志删除的过程。为了分析被压缩过的历史日志,可以使用对应压缩软件提供的工具,例如 gz 格式对应 zcat/zgrep,xz 格式对应 xzcat/xzgrep,zst 格式对应 zstdcat/zstdgrep 等等。
某段日志/错误信息是从哪个程序的源代码中的哪里输出的?
在排查问题时,有时候会需要去搞清楚是什么东西在哪里输出了我们看到的错误信息。此时可以考虑使用代码搜索网站,最常见的选择有:
- GitHub 代码搜索(需要登录),直接在搜索框输入即可。
- Debian Code Search,可以搜索 Debian 系统中所有包的源代码。
某些大型程序也有专门的搜索网站,例如 Chromium Code Search。
procfs 与 strace¶
/proc(procfs)是内核以文件系统形式向用户空间提供的查看、管理进程状态的接口。
其中 /proc/self 指向了访问文件的当前进程的信息,/proc/<pid> 则指向了 PID 对应进程的信息。
常关注的信息(不会直接从 htop 等获得的信息)有:
cwd与exe:程序的当前工作目录与可执行文件路径fd目录包含了所有程序打开的文件描述符stack:程序在内核态的栈信息,这一项信息在程序一直处于 D 状态(不可中断睡眠)时特别有用
在分析进程行为时,另一个相当有用的工具是 strace。它可以输出程序使用的所有系统调用信息,在调试许多问题的时候都可以提供很大的帮助。一些常用的命令有:
strace ls:跟踪ls的系统调用strace -f bash:跟踪bash及其 fork 出的子进程的系统调用strace -p <pid>:跟踪指定 PID 的进程的系统调用strace -e openat ls:只跟踪openat系统调用strace -ff -o /tmp/test.log bash:将bash及其 fork 出的子进程的系统调用输出到/tmp/test.log.*strace -k -yy -e mmap ls: 跟踪ls的mmap系统调用,并打印出执行此系统调用时的堆栈(-k),同时解码所有文件描述符(-yy)。这样即可追踪到每个被mmap的文件在程序的何处被引入。
Sysinternals' Procmon
Windows 系统上的类似工具是 Sysinternals 的 Procmon, 可以查看所有进程对文件系统、注册表等的操作。 有趣的是,Sysinternals 在多年前也推出了 Procmon 的 Linux 版本, 使用了 eBPF 技术实现(详见下文)。
案例:CentOS 7 容器使用 yum 安装软件的 bug
在某些配置下,可以注意到 centos:7 容器中使用 yum 安装软件时会卡住:
$ sudo docker run -it --rm centos:7 bash
[root@16c7cc5f835d /]# yum update
(略)
Updating : tzdata-2024a-1.el7.noarch 1/102
Updating : bash-4.2.46-35.el7_9.x86_64 2/102
Updating : glibc-common-2.17-326.el7_9.x86_64 3/102
Updating : nss-softokn-freebl-3.90.0-6.el7_9.x86_64 4/102
Updating : glibc-2.17-326.el7_9.x86_64 5/102
此时发现 /usr/bin/python /usr/bin/yum update CPU 占用 100%。使用 strace 跟踪 yum 的系统调用:
$ sudo strace -f -p 3163763
fcntl(441032195, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032196, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032197, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032198, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032199, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032200, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032201, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032202, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032203, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032204, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032205, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032206, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032207, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032208, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032209, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032210, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032211, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032212, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032213, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032214, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032215, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032216, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032217, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032218, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032219, F_GETFD) = -1 EBADF (Bad file descriptor)
fcntl(441032220, F_GETFD) = -1 EBADF (Bad file descriptor)
...
可以发现其在遍历所有可能的文件描述符,但是在该容器环境中,这个范围过大,导致了 yum 卡住。
搜索后可以发现这是个已知的 bug:如果容器没有限制文件描述符的范围,那么默认值就特别大:
而某些程序无法正确处理这种情况(默认文件描述符范围不大,然后一个一个去尝试操作)。
不仅是 yum,诸如 xinetd 等也有类似的问题(ref)。
strace 的输出格式并不总是最可读的形式,所以,还有一些专注于特定领域的系统调用追踪工具,比如:
- tracexec 专注于追踪 exec 系列的系统调用,能够重新构造执行的程序的 shell 命令行并显示环境变量和文件描述符相较于原始环境的差异。除此之外,在用 gdb 调试程序时可能遇到比较复杂的场景,比如被调试的程序是被一个 python 脚本启动的,或者两个需要被调试的程序之间需要通过管道通信(
a | b),这时可以通过 tracexec 方便地在execve{,at}系统调用结束时,程序开始执行前将 gdb 调试器接入想要调试的所有程序。
除 strace 以外,Linux 中还有很多用于监控、追踪系统状态的工具,如图所示:

需要根据具体情况选择合适的工具。本文亦无法详细介绍每一个工具的使用方法,因此请参考对应工具的手册。
调试符号与 gdb¶
有的时候,我们会遇到程序崩溃的情况。除了程序本身留下的日志以外,另一个重要的信息就是程序的 coredump。 coredump 中包含了程序的内存信息,通过解析 coredump,我们可以获取在程序崩溃时详细的调用栈信息,这对于排查问题非常有帮助。
在安装了 systemd-coredump 的系统上,其会自动收集程序崩溃时的 coredump;
对于正在运行的程序,也可以使用 gcore 命令来生成 coredump。
但是 coredump 还需要配合调试符号才能进行分析,否则得到的内容包括写程序的人自己都不可能看懂。
对于 Debian,可以参考 https://wiki.debian.org/HowToGetABacktrace 来获取调试符号,其他的发行版则需要阅读发行版对应的手册。
一般来讲,许多发行版目前都提供了从 debuginfod 自动获取调试符号的功能,也可以选择手动安装调试符号包。
有了调试符号之后,就可以使用 gdb 分析 coredump 了。对于 systemd-coredump,使用如下命令:
如果是 coredump 文件的形式,也可以直接调用 gdb:
如果希望运行时调试,或者直接使用 gdb 启动希望调试的程序:
$ gdb -p <pid> # 附加(attach)到指定的 pid 调试
$ gdb /path/to/program # 直接启动 gdb 并调试指定的程序
$ gdb --args /path/to/program arg1 arg2 # 启动 gdb 并调试指定的程序,同时传入参数
$ gdb --args env VAR=VALUE /path/to/program arg1 arg2 # 启动 gdb 并调试指定的程序,同时传入环境变量和参数
GNU gdb (GDB) 14.2
Copyright (C) 2023 Free Software Foundation, Inc.
...
>>> run # 启动程序,在启动程序前,可以进行断点设置等操作
在进入调试环境后,使用 bt 命令可以查看当前线程的调用栈。在调试符号配置正确的情况下,至少大部分的信息都能被显示出来(而不是一堆 ???)。
一个 coredump 的调用栈例子
>>> bt
#0 g_type_check_instance_cast
(type_instance=type_instance@entry=0x60166e80e040, iface_type=0x60166aa86e20 [GtkWidget/GInitiallyUnowned])
at ../glib/gobject/gtype.c:4217
#1 0x00007408aee7a370 in registry_handle_global
(data=0x60166e80e040, registry=<optimized out>, name=81, interface=0x60166f7c7840 "wl_output", version=<optimized out>)
at ../spice-gtk-0.42/src/wayland-extensions.c:77
#2 0x00007408ca373596 in ??? () at /usr/lib/libffi.so.8
#3 0x00007408ca37000e in ??? () at /usr/lib/libffi.so.8
#4 0x00007408ca372bd3 in ffi_call () at /usr/lib/libffi.so.8
#5 0x00007408c327f645 in wl_closure_invoke (closure=closure@entry=0x60166f7c7760, target=<optimized out>,
target@entry=0x60166ead1ff0, opcode=opcode@entry=0, data=<optimized out>, flags=1) at ../wayland-1.22.0/src/connection.c:1025
#6 0x00007408c327fe73 in dispatch_event (display=display@entry=0x60166a9ffed0, queue=0x60166a9fffc0)
at ../wayland-1.22.0/src/wayland-client.c:1631
#7 0x00007408c328013c in dispatch_queue (queue=0x60166a9fffc0, display=0x60166a9ffed0) at ../wayland-1.22.0/src/wayland-client.c:1777
#8 wl_display_dispatch_queue_pending (display=0x60166a9ffed0, queue=0x60166a9fffc0) at ../wayland-1.22.0/src/wayland-client.c:2019
#9 0x00007408c3478a39 in ??? () at /usr/lib/libgdk-3.so.0
#10 0x00007408c3444fa9 in gdk_display_get_event () at /usr/lib/libgdk-3.so.0
#11 0x00007408c3480208 in ??? () at /usr/lib/libgdk-3.so.0
#12 0x00007408c8ee8f69 in g_main_dispatch (context=0x60166aa114b0) at ../glib/glib/gmain.c:3476
#13 0x00007408c8f473a7 in g_main_context_dispatch_unlocked (context=0x60166aa114b0) at ../glib/glib/gmain.c:4284
#14 g_main_context_iterate_unlocked.isra.0
(context=context@entry=0x60166aa114b0, block=block@entry=1, dispatch=dispatch@entry=1, self=<optimized out>)
at ../glib/glib/gmain.c:4349
#15 0x00007408c8ee7162 in g_main_context_iteration (context=context@entry=0x60166aa114b0, may_block=may_block@entry=1)
at ../glib/glib/gmain.c:4414
#16 0x00007408c8c95b66 in g_application_run (application=0x60166abe9ce0 [GtkApplication], argc=<optimized out>, argv=0x0)
at ../glib/gio/gapplication.c:2577
#17 0x00007408ca373596 in ??? () at /usr/lib/libffi.so.8
#18 0x00007408ca37000e in ??? () at /usr/lib/libffi.so.8
#19 0x00007408ca372bd3 in ffi_call () at /usr/lib/libffi.so.8
#20 0x00007408c90566d1 in ??? () at /usr/lib/python3.11/site-packages/gi/_gi.cpython-311-x86_64-linux-gnu.so
#21 0x00007408c9055090 in ??? () at /usr/lib/python3.11/site-packages/gi/_gi.cpython-311-x86_64-linux-gnu.so
#22 0x00007408c9f98366 in _PyObject_Call
(kwargs=<optimized out>, args=0x7408bb5b3140, callable=0x7408c4561470, tstate=0x7408ca30d6d8 <_PyRuntime+166328>)
at Objects/call.c:343
#23 PyObject_Call (callable=0x7408c4561470, args=0x7408bb5b3140, kwargs=<optimized out>) at Objects/call.c:355
#24 0x00007408c9f6a64d in do_call_core
(use_tracing=<optimized out>, kwdict=0x7408bb575d80, callargs=0x7408bb5b3140, func=0x7408c4561470, tstate=<optimized out>)
at Python/ceval.c:7349
#25 _PyEval_EvalFrameDefault (tstate=<optimized out>, frame=<optimized out>, throwflag=<optimized out>) at Python/ceval.c:5376
#26 0x00007408ca01fae4 in _PyEval_EvalFrame (throwflag=0, frame=0x7408ca403020, tstate=0x7408ca30d6d8 <_PyRuntime+166328>)
at ./Include/internal/pycore_ceval.h:73
#27 _PyEval_Vector
(tstate=tstate@entry=0x7408ca30d6d8 <_PyRuntime+166328>, func=func@entry=0x7408c9b06020, locals=locals@entry=0x7408c9b26c80, args=args@entry=0x0, argcount=argcount@entry=0, kwnames=kwnames@entry=0x0) at Python/ceval.c:6434
#28 0x00007408ca01f4cc in PyEval_EvalCode (co=0x7408c9af8620, globals=<optimized out>, locals=0x7408c9b26c80) at Python/ceval.c:1148
#29 0x00007408ca03cd03 in run_eval_code_obj
(tstate=tstate@entry=0x7408ca30d6d8 <_PyRuntime+166328>, co=co@entry=0x7408c9af8620, globals=globals@entry=0x7408c9b26c80, locals=locals@entry=0x7408c9b26c80) at Python/pythonrun.c:1741
#30 0x00007408ca038e0a in run_mod
(mod=mod@entry=0x60166a2cd578, filename=filename@entry=0x7408c9ad4580, globals=globals@entry=0x7408c9b26c80, locals=locals@entry=0x7408c9b26c80, flags=flags@entry=0x7ffd781984f8, arena=arena@entry=0x7408c9a4f7b0) at Python/pythonrun.c:1762
#31 0x00007408ca04f383 in pyrun_file
(fp=fp@entry=0x60166a23d470, filename=filename@entry=0x7408c9ad4580, start=start@entry=257, globals=globals@entry=0x7408c9b26c80, locals=locals@entry=0x7408c9b26c80, closeit=closeit@entry=1, flags=0x7ffd781984f8) at Python/pythonrun.c:1657
#32 0x00007408ca04ecf5 in _PyRun_SimpleFileObject (fp=0x60166a23d470, filename=0x7408c9ad4580, closeit=1, flags=0x7ffd781984f8)
at Python/pythonrun.c:440
#33 0x00007408ca04d5f8 in _PyRun_AnyFileObject (fp=0x60166a23d470, filename=0x7408c9ad4580, closeit=1, flags=0x7ffd781984f8)
at Python/pythonrun.c:79
#34 0x00007408ca048098 in pymain_run_file_obj (skip_source_first_line=0, filename=0x7408c9ad4580, program_name=0x7408c9b26ef0)
at Modules/main.c:360
#35 pymain_run_file (config=0x7408ca2f3720 <_PyRuntime+59904>) at Modules/main.c:379
#36 pymain_run_python (exitcode=0x7ffd781984f0) at Modules/main.c:601
#37 Py_RunMain () at Modules/main.c:680
#38 0x00007408ca0131eb in Py_BytesMain (argc=<optimized out>, argv=<optimized out>) at Modules/main.c:734
#39 0x00007408c9c43cd0 in __libc_start_call_main
(main=main@entry=0x601669c16120 <main>, argc=argc@entry=2, argv=argv@entry=0x7ffd78198748)
at ../sysdeps/nptl/libc_start_call_main.h:58
#40 0x00007408c9c43d8a in __libc_start_main_impl
(main=0x601669c16120 <main>, argc=2, argv=0x7ffd78198748, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7ffd78198738) at ../csu/libc-start.c:360
#41 0x0000601669c16045 in _start ()
此外,bt full 可以显示当前线程完整的调用栈,thread apply all bt full 可以显示所有线程的完整调用栈。这些信息在汇报 bug 时会非常有用。
如果需要自行尝试从 coredump 获取信息,以下的命令也会有帮助:
up/down:切换到上一层/下一层调用栈info args与info locals:显示当前函数的参数与局部变量。由于编译器优化,一部分变量会变成<optimized out>,这些信息会丢失l:显示当前函数的源码print xxx:打印变量的值,参数支持表达式(需要对 C 的指针与类型系统有一定的了解)
需要注意的是,coredump 只包含了崩溃现场的信息,导致崩溃的原因有可能并不在 coredump 中:
例如在之前的执行中,程序已经向错误的位置写入数据,只是没有立刻触发问题。
这就需要考虑使用其他的方法排查问题,例如在运行时使用 valgrind 检查内存访问,或者编译时就添加 AddressSanitizer 等工具。
如果只需要看到程序的调用堆栈,不需要对程序进行调试,也可以使用 pstack 工具。
性能问题分析¶
本节介绍使用 perf 等工具进行基础的性能问题分析的方式。perf 工具的源代码随 Linux 内核分发,其也依赖于 Linux 内核头文件。在 Debian 上的包名为 linux-perf。
perf 的功能非常丰富,以下仅能介绍一小部分功能。
火焰图¶
火焰图是最常用的用于分析程序性能的图表之一,它可以直观地展示程序中函数的调用关系与耗时。生成的 SVG 文件可以使用浏览器打开并交互。

火焰图示例。点击图片可以查看完整的 SVG 文件。
火焰图按照函数调用栈的方式竖向展示程序的执行情况,底部是调用栈的最外层,每个条的宽度代表对应的函数执行的 CPU 比例。于是,越宽的条就代表了对应的函数(以及其调用的函数)占用的 CPU 时间越多。可以点击感兴趣的函数来「专注」于这个函数内部的调用栈。
SVG 火焰图由 Brendan Gregg 的 FlameGraph 项目生成,其支持包括 perf 在内的多种性能分析工具的输出。以下以 perf 为例介绍。
首先 clone FlameGraph 仓库,然后使用 perf record 命令对程序采样:
git clone https://github.com/brendangregg/FlameGraph
# 从头执行程序
perf record -F 499 --call-graph dwarf,64000 -g -- stress -c 1 -t 10
# 附加到正在运行的程序
perf record -F 499 --call-graph dwarf,64000 -g -p 12345
其中 -F 指定了采样频率为 499 Hz,-g 代表采样函数调用栈,--call-graph 参数指定了调用栈的采样方式。
为什么采样频率不使用整百的数字?
以上内容中采样频率设置为了 499 Hz。如果阅读别的教程,可以发现不少也会设置为 99 Hz。避开 500 或者 100 的原因是,某些事件可能会恰好间隔 10ms(100 Hz)或者 2ms(500 Hz)发生,如果采样频率与这些事件的周期刚好匹配,就会导致结果出现偏差。设置为恰好整百减一可以最大程度避免这种情况。
采样方式
perf 支持三种采样方式:
-
fp(默认情况):根据 frame pointer 寄存器中的信息采样。在函数调用时,frame pointer 会指向当前函数的栈帧(即函数在栈上使用的内存空间,内容包括局部变量、返回地址等)。在 x86_64 架构中,frame pointer 是 RBP 寄存器。不少编译器会选择优化掉 frame pointer 寄存器,因为其不是程序执行必需的。在 32 位的 x86 架构上,这种优化是非常有必要的,因为 x86 架构的通用寄存器数量非常少,多出一个寄存器可以有效提高程序性能。但是 x86_64 架构的通用寄存器数量提升了不少,因此一般认为这类优化对性能提升不显著,并且会给问题调试与性能调优带来困难。诸如 Ubuntu、Fedora、Arch Linux 等均已经默认开启 frame pointer。
在编译时,可以添加
-fno-omit-frame-pointer选项来禁用这种优化。 -
lbr:使用 Last Branch Record 寄存器来采样,需要 CPU 架构支持。LBR 寄存器会记录最近的分支跳转信息,有权限的程序可以配置让 LBR 寄存器仅记录call和ret指令,从而实现函数调用栈的采样。虽然不需要程序调整编译参数,但是硬件寄存器的数量是有限的,因此这种方式无法处理过深的函数调用。 dwarf:使用 DWARF 调试信息来采样。这种方式需要程序编译时开启 DWARF 调试信息(gcc -g),开销相对较高。上文中--call-graph dwarf,64000的64000代表每次采样时记录最多 64000 字节的 stack dump。
采样完成后的数据存储在 perf.data 文件中(可以使用 -o 参数修改)。接下来使用 perf script 输出 trace,并在预处理数据后,使用 FlameGraph 生成火焰图:
perf script > out.perf
FlameGraph/stackcollapse-perf.pl out.perf > out.folded
FlameGraph/flamegraph.pl out.folded > out.svg
perf report
perf.data 文件也可以使用 TUI 的 perf report 命令查看。perf report 的 annotate 功能可以展示函数内部汇编以及对应的代码(如果有调试信息)采样得到的时间占比。
注意,这种方式不适用于解释型与 JIT 类的语言,因为这一类语言的函数调用栈难以直接通过解释器/运行时的调用栈获取,需要使用各个语言的专用工具处理。
@taoky: 快速生成火焰图
我还是觉得每次都要写这么多命令有点麻烦,所以我自己一般直接用 flamegraph-rs/flamegraph,于是直接这样就可以生成了:
获取硬件计数器统计信息¶
perf stat 命令可以获取硬件计数器的统计信息,帮助了解程序的性能瓶颈:
$ perf stat uname
Linux
Performance counter stats for 'uname':
1.34 msec task-clock:u # 0.537 CPUs utilized
0 context-switches:u # 0.000 /sec
0 cpu-migrations:u # 0.000 /sec
67 page-faults:u # 50.119 K/sec
228,089 cpu_atom/instructions/u # 0.75 insn per cycle (67.70%)
<not counted> cpu_core/instructions/u (0.00%)
305,397 cpu_atom/cycles/u # 0.228 GHz
<not counted> cpu_core/cycles/u (0.00%)
41,051 cpu_atom/branches/u # 30.708 M/sec
<not counted> cpu_core/branches/u (0.00%)
3,065 cpu_atom/branch-misses/u # 7.47% of all branches
<not counted> cpu_core/branch-misses/u (0.00%)
TopdownL1 (cpu_atom) # 50.3 % tma_bad_speculation
# 16.1 % tma_retiring
TopdownL1 (cpu_atom) # 0.0 % tma_backend_bound
# 33.7 % tma_frontend_bound
0.002489347 seconds time elapsed
0.000000000 seconds user
0.002576000 seconds sys
根据 CPU 架构的不同,perf stat 默认显示的计数器信息也会存在区别。以上命令是在一台运行 Intel 12 代 i5 CPU 的机器上运行的,因此其包含了一些特殊的计数器信息:
- 大小核(core & atom)的计数器信息。
tma:Topdown Microarchitecture Analysis,Intel 提供的用于分析 CPU 的性能瓶颈的方法。- 有关使用
perf利用 TMA 方法分析程序的步骤,可参考 https://perfwiki.github.io/main/top-down-analysis/。
- 有关使用
用户也可以指定感兴趣的计数器,例如以下命令会显示 CPU 运行程序的时钟周期、命令数、缓存命中与失效信息:
$ perf stat -e cycles,instructions,cache-references,cache-misses stress -c 1 -m 1 -t 5
stress: info: [1968709] dispatching hogs: 1 cpu, 0 io, 1 vm, 0 hdd
stress: info: [1968709] successful run completed in 5s
Performance counter stats for 'stress -c 1 -m 1 -t 5':
5,988,155,941 cpu_atom/cycles/u (22.77%)
6,878,171,900 cpu_core/cycles/u (92.90%)
6,948,484,803 cpu_atom/instructions/u # 1.16 insn per cycle (22.77%)
7,087,148,185 cpu_core/instructions/u # 1.03 insn per cycle (92.90%)
6,294,530 cpu_atom/cache-references/u (22.77%)
1,730,791 cpu_core/cache-references/u (92.90%)
6,225,141 cpu_atom/cache-misses/u # 98.90% of all cache refs (22.77%)
1,593,046 cpu_core/cache-misses/u # 92.04% of all cache refs (92.90%)
5.002407973 seconds time elapsed
5.639733000 seconds user
4.324169000 seconds sys
可以查看 perf-stat(1) 了解如何获取可用的计数器的列表。
eBPF¶
本部分主要介绍 eBPF 的使用。 在遇到疑难问题时,eBPF 可以帮助我们以非常低的代价在线上系统中获取内核态与应用程序更多的信息。 对于需要获取内核信息的场景,很可能需要阅读内核源码,elixir.bootlin.com 提供了在浏览器中方便的内核源码阅读功能,支持快速跳转到符号等功能。
bcc 与 bpftrace 是两个常用的 eBPF 工具,用户可以用它们编写自己的 eBPF 程序来获取内核态信息。 此外,它们还提供了大量的(示例)工具,对一些常见的问题提供了解决方案,如下面两张图所示 (以下工具的使用请自行查阅资料):
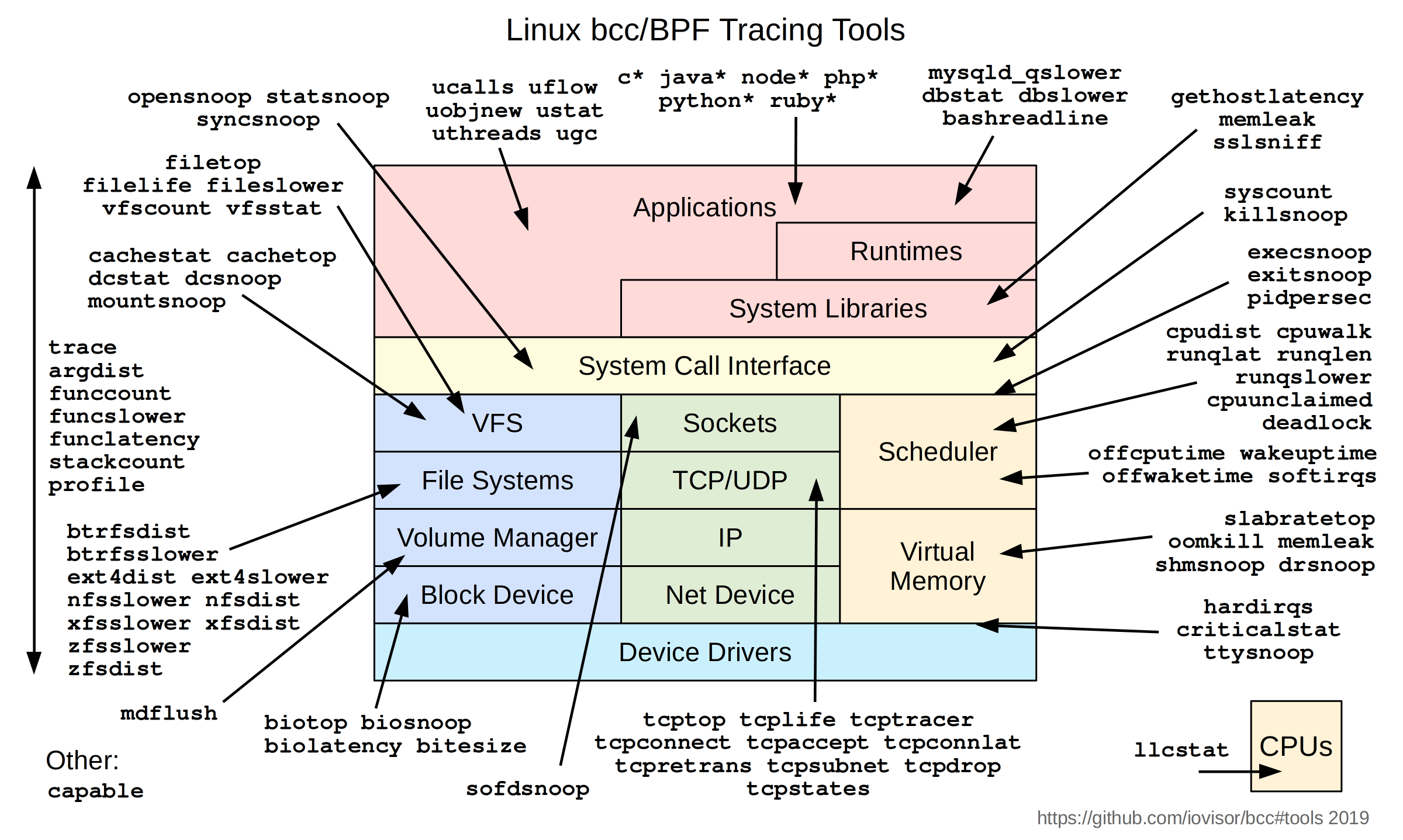
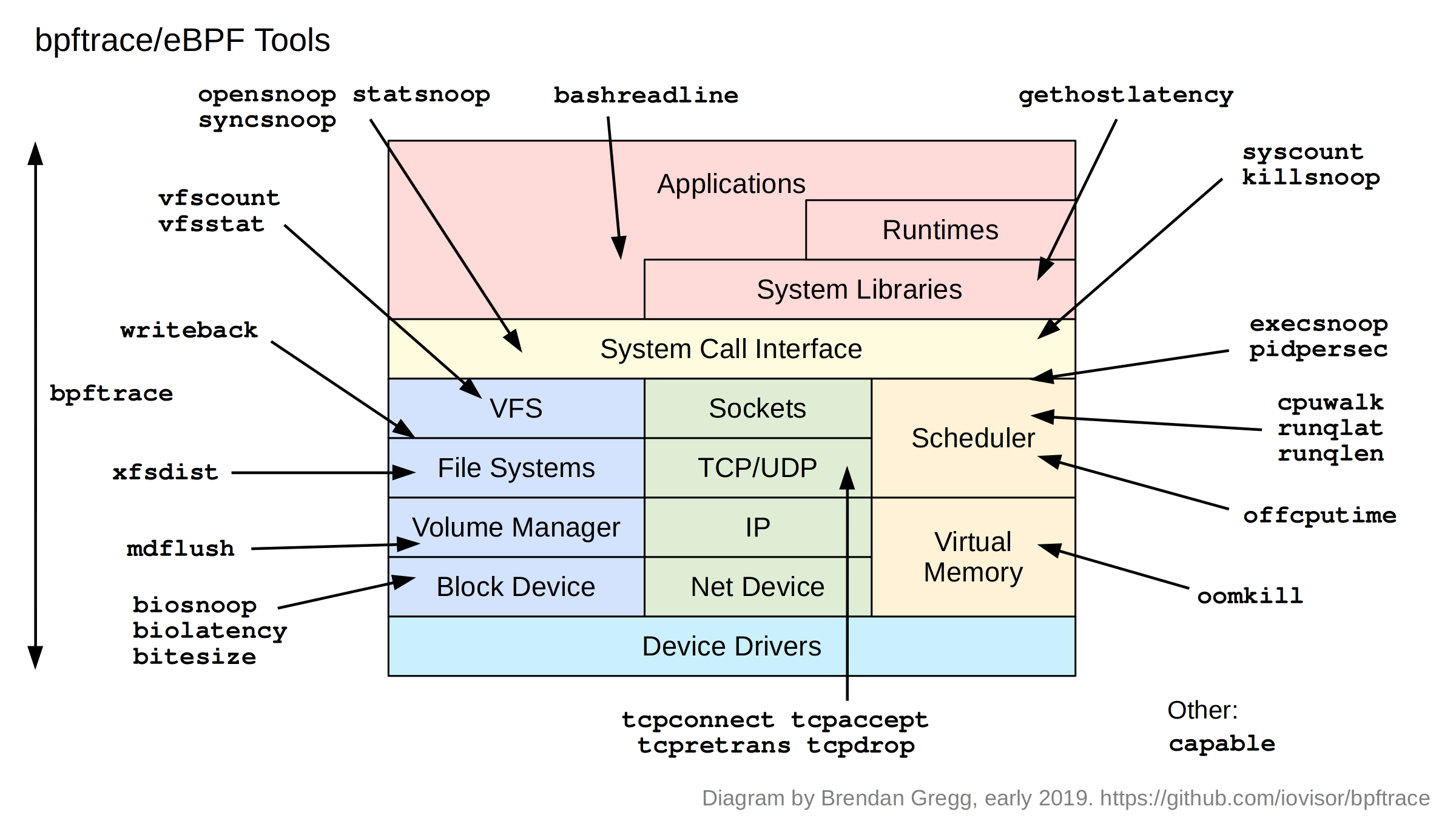
考虑到 bpftrace 使用较为简单(不需要写 C 代码),因此以下对 bpftrace 做简单介绍。
内核态¶
bpftrace 中包含了几种内核态的「探针」(probe):
- kprobe:默认在函数入口处插入 probe,也可以指定偏移量,从而在函数的任意位置插入 probe
- kretprobe:在函数返回时插入 probe,可以获取函数的返回值,不能获取函数的参数
- tracepoint:在内核预先定义的 tracepoint 处插入 probe
- kfunc/kretfunc:在函数调用/返回时插入 probe,相比于 kprobe/kretprobe,不能在任意位置插入,但是性能更好,并且可以获取到类型信息,kretfunc 也可以获取函数的参数
使用 bpftrace -l 可以获取到当前系统支持的所有 probe。一般来说,内核版本越新,支持越好。
$ sudo bpftrace -l
(省略)
tracepoint:xhci-hcd:xhci_setup_addressable_virt_device
tracepoint:xhci-hcd:xhci_setup_device
tracepoint:xhci-hcd:xhci_setup_device_slot
tracepoint:xhci-hcd:xhci_stop_device
tracepoint:xhci-hcd:xhci_urb_dequeue
tracepoint:xhci-hcd:xhci_urb_enqueue
tracepoint:xhci-hcd:xhci_urb_giveback
一个简单的例子是获取系统之后执行的所有程序(execsnoop)。
以下是一个简化的版本,输出执行了 execve() 的程序,以及其参数(文件路径):
$ sudo bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s %s\n", comm, str(args->filename)); }'
Attaching 1 probe...
code /home/username/.nix-profile/bin/docker
code /usr/lib/rustup/bin/docker
code /home/username/.local/bin/docker
code /home/username/.cargo/bin/docker
^C
这里我们可以直接使用 args->filename 获取到 execve() 的参数,因为 bpftrace 能够获取到相关的类型信息:
$ sudo bpftrace -lv tracepoint:syscalls:sys_enter_execve
tracepoint:syscalls:sys_enter_execve
int __syscall_nr
const char * filename
const char *const * argv
const char *const * envp
有的时候,你需要追踪的函数不在 tracepoint 中,此时就需要使用 kprobe/kretprobe(或者 kfunc/kretfunc),
例如下面这个追踪 try_charge_memcg 的第三个参数 nr_pages 的例子:
$ sudo bpftrace -e 'kprobe:try_charge_memcg { printf("%d\n", arg2); }' # 第一个参数是 arg0
1
1
1
2
...
^C
$ # 通常情况下,我们不希望追踪整个系统对某个内核函数的调用,只需要追踪某个进程的调用,因此可以这么写:
$ # 假设 PID 为 1234567
$ sudo bpftrace -e 'kprobe:try_charge_memcg /pid == 1234567/ { printf("%d\n", arg2); }'
1
1
...
使用 kprobe 和 kretprobe 时,一个常见的 pattern 是:kprobe 记录某种状态(例如时间或者调用参数),然后在 kretprobe 中输出。 相关的例子可以参考 bpftrace 的示例与文档。
在支持 kfunc 的环境下,可以使用 kfunc 让逻辑更加清晰:
$ sudo bpftrace -lv kfunc:try_charge_memcg
kfunc:vmlinux:try_charge_memcg
struct mem_cgroup * memcg
gfp_t gfp_mask
unsigned int nr_pages
int retval
$ sudo bpftrace -e 'kfunc:try_charge_memcg { printf("%d\n", args->nr_pages); }'
...
除了 bpftrace 这类通用型的调试工具之外,还有很多用来调试特定的问题的调试工具,比如:
- retsnoop 可以找出内核返回一个错误码的具体位置,方便在错误码含义不够明确的情况下定位更具体的出错原因。
用户态¶
eBPF 技术也可以用于用户态调试,在 bpftrace 中对应的是 uprobe 和 uretprobe。
以下面的 C++ 程序为例子:
#include <iostream>
int example(int a, int b) {
return a + b;
}
int main(void) {
for (int i = 0; i < 1024; i++) {
int a = i, b = i + 1;
std::cout << example(a, b) << std::endl;
}
return 0;
}
编译并查看符号:
$ g++ example.cpp -O0 -o example
$ nm example
0000000000004040 B __bss_start
w __cxa_finalize@GLIBC_2.2.5
0000000000004028 D __data_start
0000000000004028 W data_start
0000000000004030 D __dso_handle
0000000000003db0 d _DYNAMIC
0000000000004038 D _edata
0000000000004158 B _end
...
我们可以找到 example() 函数对应的符号:
符号的名称修饰(Name mangling)
可以注意到,上面的符号名不是 example,而是 _Z7exampleii。
C++ 以及其他某些语言(例如 Rust)会在编译期修改函数的名称,以便支持函数重载等特性。
这里的名字经过 demangle 之后就是 example(int, int)。
nm
nm 是一个用于查看二进制文件中符号的工具,可以用于查看函数、变量等的地址。
如果不加参数,那么其会列出文件中的静态符号(例如全局变量、函数等)。
对于动态链接库(.so 文件),可以使用 nm -D 来查看其暴露给应用的动态符号。
使用 uprobe 追踪 example() 函数的调用:
$ sudo bpftrace -e 'uprobe:/path/to/example:_Z7exampleii { printf("example(%d, %d)\n", arg0, arg1); }'
Attaching 1 probe...
(在另一个终端执行 ./example 之后)
example(0, 1)
example(1, 2)
...
example(1023, 1024)
编译器优化
如果上面的例子使用 -O2,那么你可能会发现这里的 bpftrace 没有输出任何内容。
这是因为编译器进行了内联优化,将 example() 函数内联到了 main() 函数中,省去了函数调用的开销。
既然没有函数调用,那么也就没有 uprobe 可以追踪的地方。
可以使用 objdump -d 来查看编译后的汇编代码,以确认是否发生了内联优化。
使用 uprobe 追踪容器中的程序
在容器中编译并运行下面的程序:
#include <iostream>
#include <random>
#include <unistd.h>
int example(int a, int b) {
return a + b;
}
int main(void) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> distr(1, 1024);
for (;;) {
int a = distr(gen), b = distr(gen);
std::cout << example(a, b) << std::endl;
sleep(1);
}
return 0;
}
尝试追踪对应程序的 example() 函数调用。
提示:procfs 中的 /proc/<pid>/root 目录可能会有所帮助。
更多的例子与说明可以参考:
补充阅读¶
书籍¶
- Performance Analysis and Tuning on Modern CPU:非常详细的关于程序性能优化的书籍,同时其练习实验 perf-ninja 也值得一看。
- Systems Performance: Enterprise and the Cloud:著名的系统性能分析专家 Brendan Gregg 撰写的关于系统性能分析的书籍,内容涵盖了从硬件到软件的各个方面。
站点¶
- Linux debugging, profiling and tracing training Course by bootlin:Bootlin 公司提供的 Linux 调试等有关的资料,包括 slides 和练习实验
- Linux Extended BPF (eBPF) Tracing Tools:Brendan Gregg 整理的 eBPF 相关的工具资料;Brendan Gregg 的博客也有很多关于系统性能分析的信息,此外本文的几张工具合集图也出自他手
- Linux Crisis Tools:Brendan Gregg 整理的 Linux 应急响应工具集列表,建议在服务器上预先安装
@taoky: journald 的一点吐槽
首先……journald 看日志太慢了,日志很多的话实在是慢。 而且
systemctl status xxx.service因为要显示最近几条日志, 也跟着慢——在 mirrors 服务器上甚至要一分多钟才能显示出服务状态。 关于这个问题,可以阅读以下讨论:然后,journald 设置按照时间的 retention 也不太方便。 比如说,如果想保留 180 天的日志的话,怎么设置 journald 呢?
MaxRetentionSec似乎不够……最后一点是,如果要实时看内核态日志,我更推荐用
dmesg -w,因为颜色更好看一些。