基础知识简介¶
主要作者
本文编写中
在服务器运维的过程中,虚拟化技术的使用十分常见。运维人员可能会将服务器划分为若干虚拟机进行使用,或使用容器技术将应用进行包装与隔离;在需要管理大量服务器的场景下,虚拟化技术能够为集群管理提供底层支持,极大地提高了管理效率。
本部分介绍与虚拟化技术有关的常用术语和基础理论知识。
虚拟化技术简介¶
虚拟化技术是一种资源管理技术,它在下层计算资源与上层软件之间添加了一层抽象层,称为虚拟化层。虚拟化层负责分割、隔离并管理计算资源,并将资源划分为多个抽象的资源实例,提供给上层软件使用。上层软件拥有对抽象资源的完全控制权,然而,其对物理资源的使用会由虚拟化层进行调度和限制。
使用虚拟化技术可以带来许多好处:
- 资源隔离:在虚拟化层未被攻击成功的前提下,即使一个虚拟化实例被攻击,也不会影响其他虚拟化实例,从而提高安全性。
- 资源共享:一台物理主机可以运行多个虚拟化实例,每个虚拟化实例能够使用的资源都可以弹性分配,从而提高资源利用率。
- 环境迁移:虚拟化实例是软件定义的,抽象于具体硬件,因此虚拟化实例可以方便地移植到不同机器上运行。
根据虚拟化层所在的层级不同,虚拟化技术可以分出以下两种常见类型:
- 硬件虚拟化(Hardware virtualization)
- 操作系统级虚拟化(OS-level virtualization)
以下将具体介绍这两类虚拟化技术。
硬件虚拟化¶
概述¶
在硬件虚拟化技术中,物理主机被分割为一台或多台虚拟机(Virtual Machine)。每台虚拟机都可以看作一台独立的“计算机”,拥有自己的虚拟硬件(CPU、内存、硬盘、网络接口等),运行自己的操作系统和应用程序,通过虚拟化技术共享物理主机的硬件资源。
硬件虚拟化使得一台物理主机能够同时运行多个不同的操作系统,此时,被虚拟化的下层资源即为 CPU、内存、I/O 设备等硬件资源。用于创建、管理和执行虚拟机的虚拟化层被称为 Hypervisor,有时也被称为 Virtual Machine Monitor(VMM)。被虚拟化的物理主机称为宿主机(Host),而分割出的虚拟机称为客户机(Guest)。
在 1973 年的论文《Architectural Principles for Virtual Computer Systems》中,Robert P. Goldberg 将 Hypervisor 分成以下两类:
-
Type-1/Native/Bare-metal Hypervisor
- Hypervisor 直接运行在硬件上,可以直接调度硬件资源
- 性能损耗低,但使用的灵活度也较低,适合在服务器环境下使用
- 例:VMware ESXi、Xen、Microsoft Hyper-V
-
Type-2/Hosted Hypervisor
- Hypervisor 作为宿主机操作系统上的应用程序运行
- 需要通过操作系统实现资源调度,因此性能损耗较高
- 例:VMware Workstation、Oracle VM VirtualBox
而 Linux KVM 的情形较为特殊:
- 作为内核模块,KVM 将 Linux 内核转变为一个 Type-1 Hypervisor,同时又保留了内核的全部功能,由 KVM 创建和调度的虚拟机会与内核下运行的常规进程共享硬件资源
- KVM 不负责硬件模拟,而是在内核态提供 CPU 和内存虚拟化支持,结合硬件辅助虚拟化技术实现加速,因此常与用户态的 QEMU 结合使用,称为 QEMU/KVM
关于 QEMU/KVM 的更多介绍,请参考本文档的 QEMU/KVM 部分。
完整的硬件虚拟化解决方案除了提供 Hypervisor 这样的虚拟化基础设施之外,一般还会附带图形化管理界面和命令行接口,帮助管理员完成虚拟机配置,可以参考下文 常见服务器虚拟化方案 的配图。
x86 虚拟化实现¶
对于 x86 平台,有多种技术路线来实现硬件虚拟化,包括:
-
完全虚拟化(Full Virtualization)
- 虚拟化实现集中在 Hypervisor 上,操作系统可以不经修改地在 Hypervisor 上运行
- 总体来说,兼容性好,但性能可能较为低下
-
半虚拟化(Paravirtualization)
- 操作系统与 Hypervisor 通过预先约定好的接口协作运行,一般需要通过修改操作系统内核,或向操作系统中添加驱动来实现
- 性能上一般强于完全虚拟化,但兼容性上可能略逊一筹
-
硬件辅助虚拟化(Hardware Assisted Virtualization)
- 通过集成虚拟化操作相关的硬件,以提高性能,简化虚拟化相关的软件实现,一般与上述两种虚拟化方式结合使用
- 目前,x86 平台上几乎所有 Hypervisor 的高效运行都依赖于这类技术
你的 CPU 是否支持硬件虚拟化扩展?
现代主流的 x86-64 CPU 都应当支持这类扩展,可以使用 lscpu 等工具来检查这一点:
⟩ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 20
On-line CPU(s) list: 0-19
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i7-12700H
CPU family: 6
Model: 154
Thread(s) per core: 2
Core(s) per socket: 14
Socket(s): 1
Stepping: 3
CPU(s) scaling MHz: 20%
CPU max MHz: 4700.0000
CPU min MHz: 400.0000
BogoMIPS: 5376.00
Flags: ... vmx ept ept_ad ...
Virtualization features:
Virtualization: VT-x
# 以下输出省略
# ...
其中,Flags 中的 vmx 表示 CPU 支持 Intel 虚拟机扩展(VT-x)技术,ept 表示 CPU 支持扩展页表(Extended Page Tables)技术,这些硬件辅助虚拟化技术也将在下文提及。
以下将从 CPU、内存、I/O 虚拟化三个部分来简要介绍硬件虚拟化的实现。这里提到的实现技术可能已经过时,但它们有助于理解实现虚拟化的基本原理。
CPU 虚拟化¶
CPU 虚拟化的一个经典架构被称为「Trap & Emulate」,其大致思想是:非敏感指令在 Guest OS 上直接执行,敏感指令陷入到 Hypervisor 进行模拟。然而,这种模型对于硬件架构设计存在要求,而 x86 架构在最初设计时并未考虑到虚拟化的场景,无法满足前提条件,也就无法直接使用这种架构,在 x86 虚拟化发展的早期,只能采取一些变通方法。
对于完全虚拟化来说,一种实现是采用直接指令执行与二进制翻译相结合的方式,在运行时动态分析 Guest OS 执行的指令,用二进制翻译模块来替换掉其中难以虚拟化的指令,VMware Workstation 在早期就采用这种 CPU 虚拟化的方法。然而,动态二进制翻译实现起来相对复杂,且可能会带来较大的运行时开销。
至于半虚拟化,以 Xen 最初的实现 为例,Hypervisor 运行在 Ring 0,Guest OS 被修改以在 Ring 1 运行,而 Guest OS 上的应用程序仍然在 Ring 3 运行。因此,当 Guest OS 试图直接执行特权指令时,会因为权限不足而失败;取而代之地,Guest OS 需要通过 Hypercall 接口陷入到 Hypervisor 中,才能执行特权指令。除此之外的一些设计:
- 异常处理:Guest OS 的异常处理大体与原生 x86 环境一致,只是在某些特权操作上(如 Page Fault 的处理)需要通过 Hypercall 获得 Hypervisor 的协助,以及在 System Call 时通过一个 Fast Handler 来减少开销
- 中断处理:采用一个异步事件通知系统,称为 Event Channel,作为对硬件中断的虚拟化
到了 2006 年前后,Intel 与 AMD 先后发布了 VT-x 和 AMD-V 指令集扩展,从硬件层面提供了对虚拟化的支持。以 VT-x 为例,其引入了两个新的 CPU 运行模式(VMX root/non-root operation),分别交由 Hypervisor 和 Guest OS 使用,并从硬件层面实现权限控制。
内存虚拟化¶
对于操作系统内核来说,内存资源的高效调度建立在对物理内存地址空间的两个假设上:从零开始、内存地址连续;而对于需要同时运行多个操作系统的 Hypervisor 来说,需要高效地调度内存资源,尽可能满足每个操作系统对内存的需求。
目前,主流操作系统使用页(Page)为单位来管理内存。在非虚拟化的环境下,操作系统使用页表将虚拟内存地址转换到物理内存地址,用于辅助完成这一转换的硬件被称为内存管理单元(Memory Management Unit,MMU)。主流 x86 操作系统的虚拟内存管理功能都相当程度地依赖于 MMU,因此,在虚拟化环境下,Hypervisor 需要实现 MMU 虚拟化。
目前软件实现的内存虚拟化,主要分为以下两种:
-
完全虚拟化:Shadow page table(影子页表)
- Hypervisor 为每个 VM 都维护一张影子页表,将 Guest OS 中的虚拟地址翻译为 Host 的物理地址
- 性能开销大
-
半虚拟化:以 Xen 最初的实现 为例
- Guest 和 Hypervisor 共享一张页表,但 Guest 的内存访问请求都要经过 Hypervisor 的审计,Hypervisor 通过使用额外的内存管理机制(如内存分段、额外的权限设置等)来确保 Guest 的内存访问合法
- 效率较高,但需要通过修改 Guest OS 的内存管理模块来实现
而内存虚拟化的硬件辅助技术,被称为二级地址转换技术(Second Level Address Translation,SLAT),通过扩展页表结构,在硬件上直接支持 Guest Virtual Address -> Guest Physical Address -> Host Physical Address 这两层地址转换,如 Intel 的 Extended Page Table(EPT)和 AMD 的 Rapid Virtualization Indexing (RVI) 技术。
I/O 虚拟化¶
在非虚拟化的环境下,操作系统内核通过驱动与 I/O 设备进行交互。从 CPU 的角度看,与设备的交互方式一般分为以下三种:
- 中断:当设备发生特定 I/O 事件时,通过中断信号通知 CPU,促使操作系统及时响应处理
- 寄存器访问:CPU 通过读写设备寄存器来控制设备状态或获取设备数据
- DMA:设备直接与内存进行数据交换,无需 CPU 介入控制
而在虚拟化架构中,Guest OS 与物理 I/O 设备之间多出了一个虚拟化层,它们之间的交互必须由虚拟化层妥善处理。为此,I/O 虚拟化需要:
- 向 Guest OS 提供设备接口
- 截获并处理 Guest OS 向设备发起的访问操作
以下将讨论几类主流的 I/O 虚拟化的实现方式。
设备仿真¶
对于一些实现简单,且性能要求不高的 I/O 设备(如键盘、鼠标、简单网卡等),可以采用纯软件方式来完全模拟已有物理硬件的行为。
此时,Guest OS 可以直接使用现有的、为物理硬件实现的驱动来操作设备,但对于 I/O 吞吐量较大的设备来说,纯软件实现可能带来无法忽略的性能开销。
半虚拟化¶
在这种架构中,Guest OS 通过在 I/O 子系统上加以修改,能够感知到自己运行在虚拟化环境中,并与 Hypervisor 协同工作。
以 Xen 使用的「分离驱动」架构为例。在这种架构中,驱动被分为两个部分:运行在 Guest OS 上的前端驱动(front-end driver)和运行在 Hypervisor 上的后端驱动(back-end driver)。前端驱动向 Guest OS 提供几类标准的设备接口,而后端驱动则负责操作实际物理硬件,前后端驱动之间通过共享内存,使用一个被称为 I/O ring 的数据结构来实现异步数据交换。
这种实现避免了设备仿真中硬件模拟开销较大等问题,Guest OS 通过采用经过性能优化的通信接口与 Hypervisor 协同工作,在 I/O 性能上优于完全的软件仿真。
Virtio
Virtio 是一套 I/O 半虚拟化开放标准,其同样采用分离驱动的架构,旨在规范各类 I/O 设备(如网络、存储设备等)的数据传输和事件处理方式,提升虚拟化环境的效率和兼容性。
Virtio 的基本架构如下图所示,详细标准可以参考 spec。

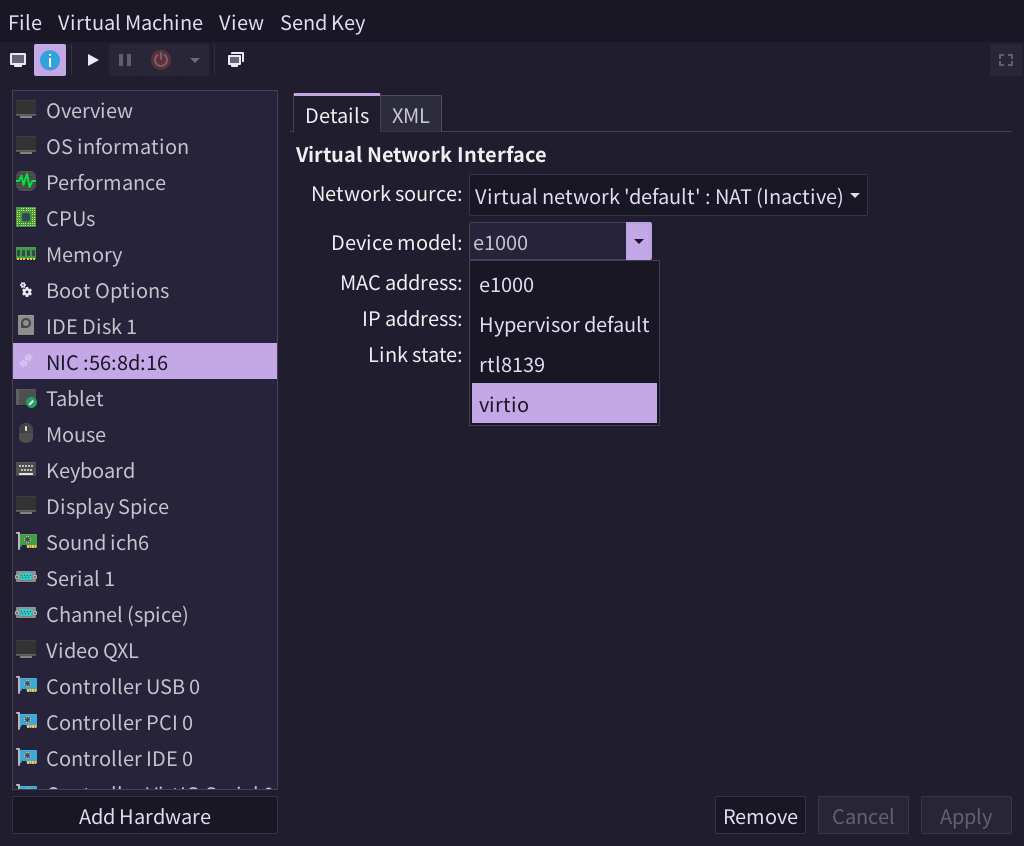
如下图中的 virt-manager 界面,网卡可以选择使用 Virtio 设备模型:
设备直通¶
在设备直通技术中,Hypervisor 将物理 I/O 设备直接分配给特定的虚拟机,使得该虚拟机能够直接与硬件进行交互,而无需经过中间的软件仿真或分离驱动层。这种方式可能依赖于硬件支持(例如 Intel VT-d 或 AMD IOMMU)来实现 DMA 重映射和中断隔离等功能。
设备直通的性能是最好的,几乎能够获得原生的 I/O 性能,但独占设备使得其灵活性稍差,在配置上可能会略微复杂,并且可能会存在兼容性问题。
Single-Root Input/Output Virtualization (SR-IOV)
SR-IOV(单根 I/O 虚拟化)是一种硬件虚拟化技术,它允许单个物理 PCIe 设备划分出多个独立的虚拟设备。具体来说,SR-IOV 将物理设备分为两类:
- 物理功能(PF):由管理程序使用,负责设备的配置和分配资源。
- 虚拟功能(VF):供虚拟机直接使用,几乎拥有与物理设备相同的功能,但资源受限。
这种分离使得虚拟机可以直接访问 VF,从而绕过大部分 hypervisor 层的干预,实现接近裸机的 I/O 性能,同时降低了虚拟化开销。SR-IOV 技术在高性能网络、存储等领域应用广泛,特别适用于数据中心和云计算环境。
IOMMU
IOMMU(输入/输出内存管理单元)是一种硬件虚拟化技术,旨在为设备的直接内存访问(DMA)提供地址转换和内存保护。它通过将设备请求中的虚拟地址映射到实际物理内存地址,同时对设备访问进行权限检查,从而实现:
- 内存隔离:防止设备越界访问,确保不同虚拟机或系统组件间的内存安全隔离。
- DMA 重映射:允许虚拟机拥有独立的 DMA 地址空间,提高虚拟化环境中的数据传输效率和安全性。
- 增强系统稳定性与安全性:有效阻止恶意或错误设备对内存的直接干扰,降低系统风险。
这种机制特别适用于虚拟化和高性能计算环境,在保护系统内存安全的同时,也确保了设备高效、可靠的数据传输。
操作系统层虚拟化¶
在操作系统级虚拟化(OS-level virtualization)中,虚拟化的对象是操作系统内核及其调度的系统资源,而不像硬件虚拟化那样直接对硬件资源进行虚拟化。每个虚拟化实例都认为自己独占操作系统内核及其所调度的资源,但实际上,这些虚拟化实例是共享内核资源的,并且仍受到操作系统内核的调度与限制。
这一类虚拟化技术一般依赖于操作系统内核提供的隔离与资源限制功能。例如,FreeBSD 内核提供的主要机制被称为 jail,以系统调用的形式提供使用接口,用于创建多个隔离的用户环境,提供更高的安全性;而 Linux 内核提供的机制比较多样化,例如:
- namespaces:将全局系统资源(PID、网络、挂载点等)隔离到不同的命名空间中,使得每个进程组拥有独立的资源视图
- cgroups:对进程组的使用的硬件资源(CPU、内存、磁盘 I/O 等)进行限制、监控和管理
- seccomp:限制进程所能够使用的系统调用
目前流行的、生态较好的虚拟化技术被称为容器(Containers),我们常用的 Docker 就属于一种容器实现。与 FreeBSD jail 相比,容器技术注重软件的可分发性,在 DevOps 领域中得到了广泛使用;当然,只要配置得当,容器同样也能实现较为可靠的安全隔离作用。关于容器技术的详细介绍,请参考本文档的 容器 部分。
与硬件虚拟化相比,操作系统级虚拟化的开销较小,也不依赖于硬件支持,但受到实现原理的限制,无法运行不同内核的操作系统。
常见服务器虚拟化方案¶
Proxmox VE (PVE)¶
Proxmox Virtual Environment(简称 Proxmox VE、PVE)是一个开源的服务器虚拟化环境 Linux 发行版。其使用基于 Ubuntu 的定制内核,包含安装程序、网页控制台和命令行工具,并且提供了 REST API 进行控制。
Proxmox VE 支持两类虚拟化技术:基于容器的 LXC 和硬件抽象层全虚拟化的 KVM。
VMware ESXi¶
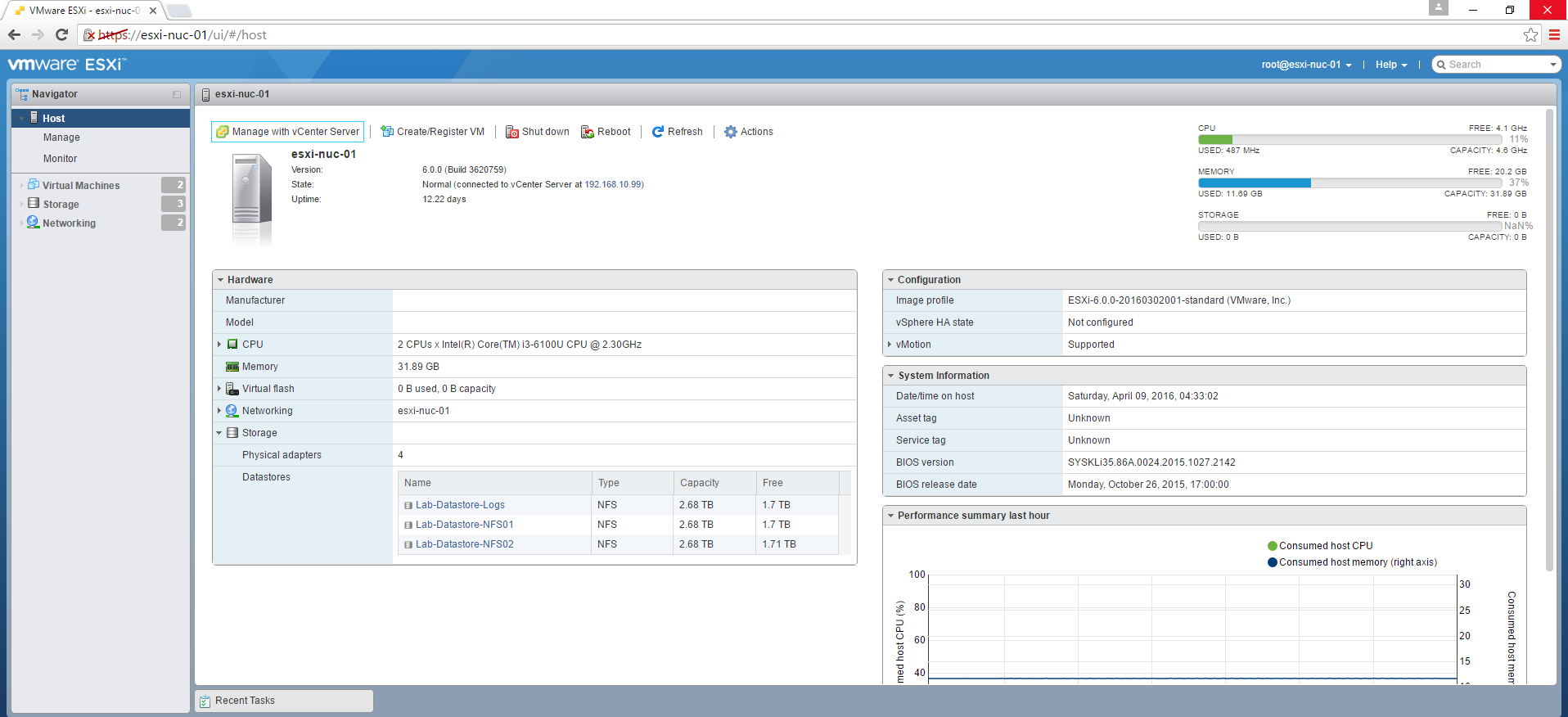
VMware ESXi(简称 ESXi)是由 VMware 公司开发的一款企业级 Type-1 Hypervisor,其提供了图形化管理工具(Web UI)、命令行接口(ESXi Shell 及配套工具)以及 API 接口,便于管理员进行虚拟机管理和自动化运维。
ESXi 可以通过与 VMware vSphere 套件集成,实现如热迁移(vMotion)、高可用性(HA)等高级功能。
需要注意的是,ESXi 及 vSphere 是闭源的付费软件,并且从 2024 年开始不再提供免费版本。
Microsoft Hyper-V¶
Microsoft Hyper-V(简称 Hyper-V)是微软公司开发的一款企业级虚拟化平台,集成于 Windows Server 中,同时也可用于 Windows 10 Pro/Enterprise 版本。它提供了图形化管理工具 Hyper-V Manager,也可以使用 PowerShell 等命令行接口进行管理。
Hyper-V 支持动态内存管理、虚拟机快照、实时迁移(Live Migration)和复制(Replica)等高级功能,同时可以与 System Center Virtual Machine Manager (SCVMM) 集成,进一步提高数据中心的虚拟化管理效率。
Xen¶
Xen(通常称为 Xen Hypervisor 或 Xen Project)是一款开源免费的 Type-1 Hypervisor,支持半虚拟化(PV)和完全虚拟化(HVM)技术。其最初于 2003 年由剑桥大学计算机实验室开发,目前由 Linux Foundation 开发与维护,得到了 Intel、AMD、Citrix、AWS 等厂商的广泛支持。
Xen 是 x86 半虚拟化技术的先驱,其经典论文《Xen and the art of virtualization》对虚拟化领域产生了深远影响;同时,在 KVM 尚未普及的早期阶段(2015 年以前),Xen 是云服务厂商和大型数据中心的主流选择。

参考资料¶
- 阿里云课程 - 虚拟化技术入门
- CTF Wiki - 虚拟化基础知识
- VMware White Paper - Understanding Full Virtualization, Paravirtualization, and Hardware Assist
- Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3C: System Programming Guide, Part 3
- Virtio: An I/O virtualization framework for Linux
- Intel® Virtualization Technology for Directed I/O
- Xen Project Software Overview
- Edouard Bugnion, Scott Devine, Mendel Rosenblum, Jeremy Sugerman, and Edward Y. Wang. 2012. Bringing Virtualization to the x86 Architecture with the Original VMware Workstation. ACM Trans. Comput. Syst. 30, 4, Article 12 (November 2012), 51 pages. https://doi.org/10.1145/2382553.2382554
- Paul Barham, Boris Dragovic, Keir Fraser, Steven Hand, Tim Harris, Alex Ho, Rolf Neugebauer, Ian Pratt, and Andrew Warfield. 2003. Xen and the art of virtualization. SIGOPS Oper. Syst. Rev. 37, 5 (December 2003), 164–177. https://doi.org/10.1145/1165389.945462